[:en]We are studying the semantic indexing method for associating other texts semantically similar and recommending them as an example to the arbitrary sites of the text read and written by a user in this project. Moreover, our subjects include paraphrasing, error correction, and template extraction for sentence generation, with the aim of developing a practical application that assists paper writing in English for non-native speakers.
Building a Writing Assistance System Based on Communicative Functions of
Formulaic Expressions for Scholarly Papers
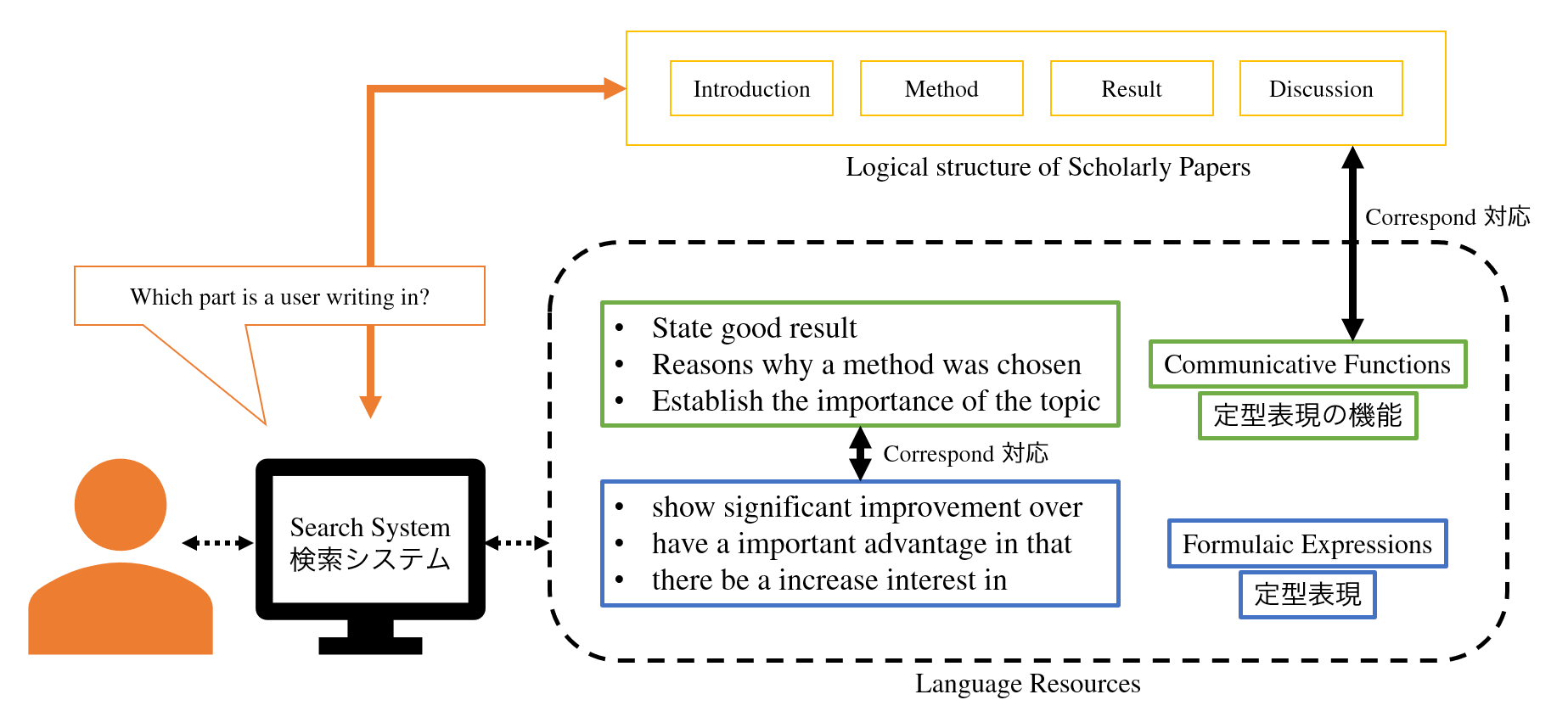
Formulaic expressions have been found to be helpful in writing scholarly papers, but it is costly to search for desirable formulaic expressions because there are few digitalised resources and existing retrieval systems are not efficient enough to save labour. Key-word-based searching, which most existing systems adopt, does not provide users with a wide variety of formulaic expressions. To alleviate this problem, we proposed a new scheme of formulaic expression retrieval that utilises communicative functions of formulaic expressions (Iwatsuki & Aizawa, COLING 2018
[link]).
It is widely known that the usage of formulaic expressions and communicative functions differs across disciplines, which raises the need for domain-specific databases of formulaic expressions labelled with communicative functions.
In order for efficiently constructing such domain-specific databases, we are developing a method for automatically annotating formulaic expressions with communicative functions (Iwatsuki et al., LREC 2020 [link]). Additionally, we also developed an evaluation dataset for the formulaic expression extraction, which had been evaluated by hand before (FECFeval [link]).
Distributed representation for similar sentence search
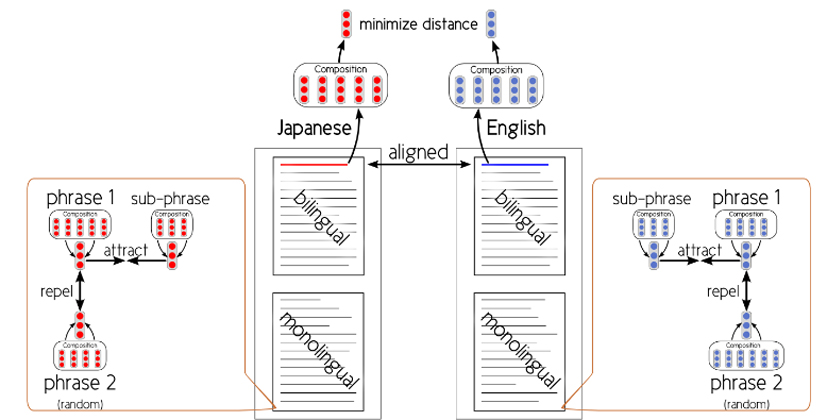
We propose a neural network that learns the semantic expression of phrases based on a novel standard called Inclusion criterion, which has implemented a multilanguage similar sentence search function. Furthermore, we have applied the proposed method to a Japanese–English bilingual corpus extracted from papers, and prepared a demonstration tool for English composition support CroVeWA. (Hubert et al.: NAACL HLT 2015 demo [link], ICLR 2015 short [link])[:ja]ユーザが読み書きするテキストの任意の箇所に、意味的に類似する他のテキストを対応づけて用例として推薦するための意味インデクシング法の研究を進めます。また、言い換えや誤り訂正、文生成のためのテンプレート抽出などの課題にも取り組み、情報学分野を適用対象として、非母語話者の英語論文執筆を支援する実用的なアプリケーションの開発を目指します。
定型表現の機能に着目した英語論文の執筆支援システムの構築
英語論文の執筆においては,定型表現の利用が効率的であることがこれまで知られてきましたが,実際に定型表現を利用するには大きな負担がかかっています。公開されている定型表現集の多くは紙媒体であり,また電子化されているものであっても,効率よく検索する計算機システムがないため,論文執筆の際に都度参照するには時間がかかりすぎるという問題点がありました。既存の検索システムは,ユーザの入力をクエリとするキーワード検索を採用しているため,ユーザに対して多様な定型表現を提示することが困難です。そこで本研究では,論文の修辞構造に依拠した定型表現の「伝達機能」(communicative function)を用いて,多様な定型表現を効率よく検索する手法を提案しました (Iwatsuki & Aizawa, COLING 2018 [link])。
定型表現と伝達機能は,分野によって異なることが知られています。そのため,分野ごとに伝達機能ラベル付き定型表現データベースを構築する必要があります。そこで本研究では、分野ごとの論文コーパスに対してアノテーションを自動付与して、効率よく定型表現および伝達機能のデータベースを作成する手法を開発しています。また,抽出した定型表現が妥当なものであるかについては,これまで人手による評価が中心でしたが,このことが定型表現の自動抽出に関する研究上の大きな障壁となっていました (Iwatsuki et al., LREC 2020 [link])。そこで,定型表現抽出システムの自動評価を行うためのデータセット FECFeval を作成し,公開しています。
分散意味表現を用いた類似文検索
「Inclusion criterion」と呼ぶ新しい基準に基づき句の意味表現を学習するニューラルネットワークを提案し、言語横断的な類似文検索機能を実現しました。また提案手法を論文から抽出した和英対訳文コーパスに適用して、英作文支援のデモツール CroVeWAを試作しました。(Hubert et al.: NAACL HLT 2015 demo [link], ICLR 2015 short [link])[:]